Open Annotation Data Model PrimerCommunity Draft, 14 January 2013 |
Open Annotation Data Model PrimerCommunity Draft, 14 January 2013 |
This document provides an intuitive introduction and guide to the Open Annotation Data Model [OA-DM], an interoperable framework for creating associations between related resources, annotations, using a methodology which conforms to the Architecture of the World Wide Web. This primer explains the fundamental Open Annotation Data Model concepts and provides examples of its use. The primer is intended as a starting point for those wishing to create or use Open Annotation Data Model compliant annotation data.
This section describes the status of this document at the time of its publication. Other documents may supersede this document.
Copyright © 2012-2013 the Contributors to the Open Annotation Core Data Model Specification, published by the Open Annotation Community Group under the W3C Community Contributor License Agreement (CLA). A human-readable summary is available.
This document was published by the Open Annotation Community Group. It is not a W3C Standard nor is it on the W3C Standards Track. Please note that under the W3C Community Contributor License Agreement (CLA) there is a limited opt-out and other conditions apply. Learn more about W3C Community and Business Groups.
This document has been made available to the Open Annotation Community Group for review, but is not endorsed by them. This is a working draft, and it is not endorsed by the W3C or its members. It is inappropriate to refer to this document other than as "work in progress".
Please send general comments about this document to the public mailing list: public-openannotation@w3.org (public archives).
Annotating, the act of creating associations between distinct pieces of information, is a pervasive activity online in many guises but lacks a structured approach. Web citizens make comments about online resources using either tools built in to the hosting web site, external web services, or the functionality of an annotation client. Comments about photos on Flickr, videos on YouTube, people's posts on Facebook, or mentions of resources on Twitter could all be considered as annotations associated with the resource being discussed. In addition, there a plethora of closed and proprietary web-based "sticky note" systems, and stand-alone multimedia annotation systems. The primary complaint about all of these systems is that the user created annotations cannot be shared or reused, due to a deliberate "lock-in" strategy within the environments where they were created, or at the very least the lack of a common approach to expressing the annotations.
The Open Annotation data model provides an extensible, interoperable framework for expressing annotations such that they can easily be shared between platforms, with sufficient richness of expression to satisfy complex requirements while remaining simple enough to also allow for the most common use cases, such as attaching a piece of text to a single web resource.
Unlike previous attempts at annotation interoperability, the Open Annotation system does not prescribe a protocol for creating, managing and retrieving annotations. Instead it describes a web-centric method, promoting discovery and sharing of annotations without clients or servers having to agree on a particular set of operations on those annotations.
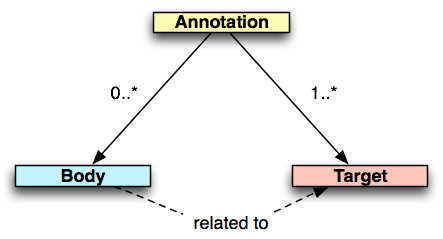
In OA, an Annotation is considered to be a set of connected resources. The simplest set of resources characterizing the Annotationi is depicted in fig. 1 and consists of (i) the annotation instance, a de-facto reification of the annotation (depicted in yellow), (ii) one or more targets. what we are annotating (depicted in pink), and (iii) zero or more bodies that, if present, represent the content of the annotation or the information which is annotating the target, or targets (depicted in light blue).
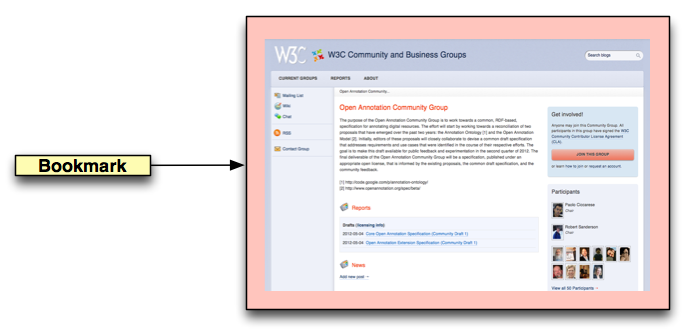
The Annotation can be as simple as a bookmark that targets a webpage and does not have a body. In the example in fig. 2, the target is the Open Annotation Collaboration Group homepage and the Annotation does not exhibit any body.
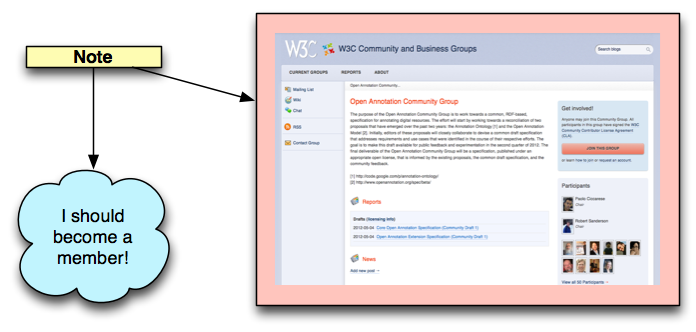
When the body exists, the Annotation usually conveys that the body is "somehow about" the target. This is the case of the note in the example in fig. 3, where the target is the Open Annotation Community Group homepage and the Annotation does exhibit a textual body.
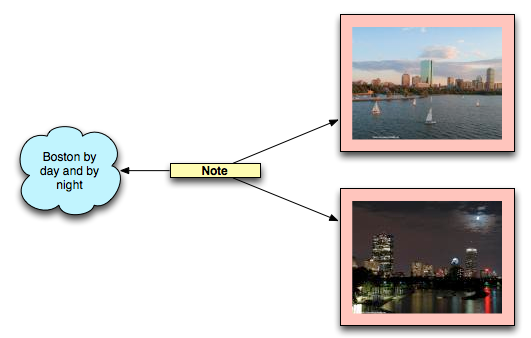
An Annotation can target multiple entities as in the note depicted in fig. 4, where the targets are two images and the Annotation does exhibit a textual body.
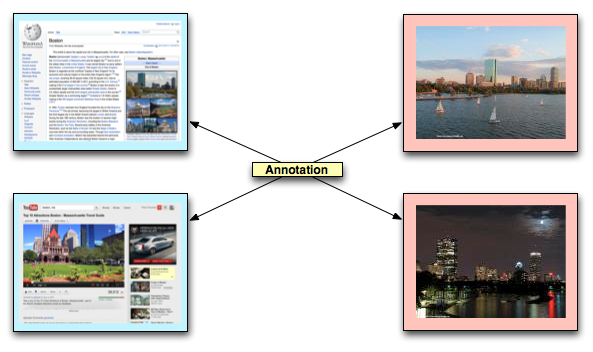
An Annotation can consists of multiple bodies and can target multiple entities as in the example depicted in fig. 5, where the Wikipedia page of Boston and a YouTube video about Boston are declared "somehow about" the two targeted pictures.
In the next sections, we will provide detailed examples showcasing the basic features of the Open Annotation model. Additional examples of how to model and implement specific situations are available in the Annotation Cookbook.
Examples throughout the document will be conveyed as both a diagram and in the Turtle RDF format [TURTLE]. The Turtle examples do not provide namespace declarations, and should be considered following these namespaces:
| Prefix | Namespace | Description |
|---|---|---|
| oa | http://www.w3.org/ns/oa# | The Open Annotation ontology |
| cnt | http://www.w3.org/2011/content# | Representing Content in RDF |
| dc | http://purl.org/dc/elements/1.1/ | Dublin Core Elements |
| dcterms | http://purl.org/dc/terms/ | Dublin Core Terms |
| dctypes | http://purl.org/dc/dcmitype/ | Dublin Core Type Vocabulary |
| foaf | http://xmlns.com/foaf/0.1/ | Friend-of-a-Friend Vocabulary |
| prov | http://www.w3.org/ns/prov# | Provenance Ontology |
| rdf | http://www.w3.org/1999/02/22-rdf-syntax-ns# | RDF |
| rdfs | http://www.w3.org/2000/01/rdf-schema# | RDF Schema |
| skos | http://www.w3.org/2004/02/skos/core# | Simple Knowledge Organization System |
| trig | http://www.w3.org/2004/03/trix/rdfg-1/ | TriG Named Graphs |
The diagrams of the examples use the following style:
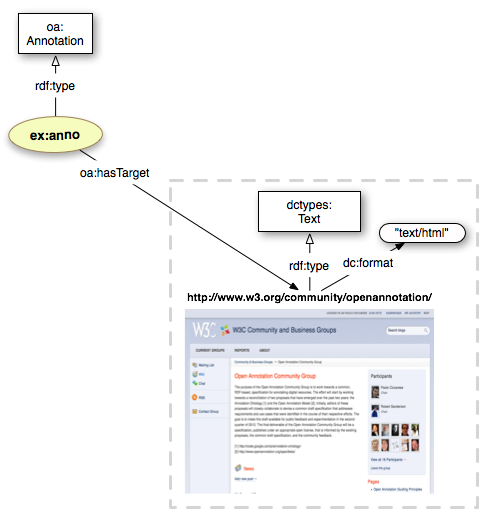
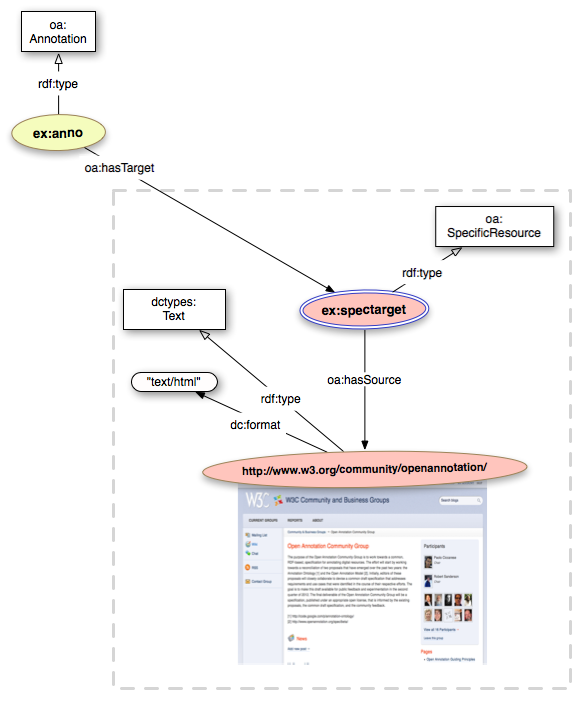
rdf:type) is depicted as a straight black line with white arrow headoa:Annotation' is a real class)In order to rapresent a Bookmark of the W3C Open Annotation Community Group homepage, we start by creating an instance of the oa:Annotation class; then we link such instance to the webpage (Target) identified by the homepage URI http://www.w3.org/community/openannotation/. Adding the Target content type and the dc:format (dctypes:Text and "text/html"), can be useful for applications consuming the annotation.
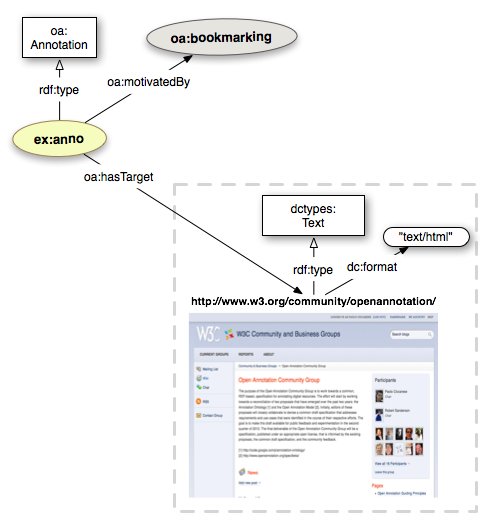
We can then provide the oa:Motivation that encodes the reason(s) why the Annotation was created. In this specific case, the Motivation is oa:bookmarking:
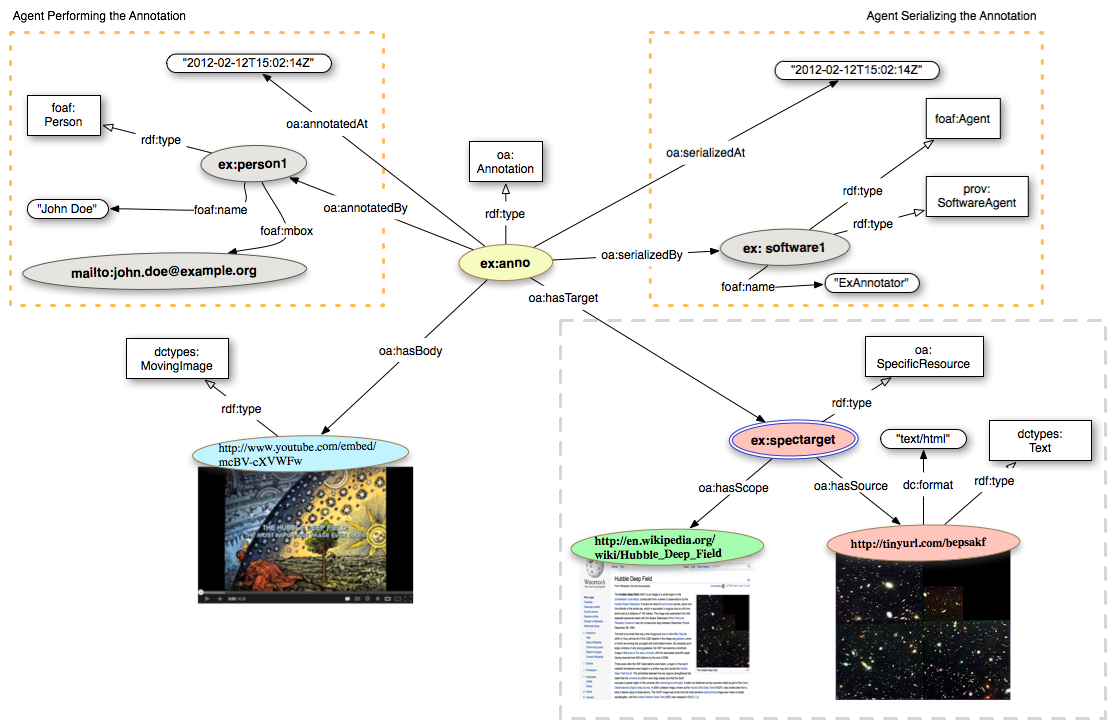
Next, we are going to provide the Provenance information. The Open Annotation model allows to encode both the agent that created the annotation and the agent that took care of the serialization of the annotation.
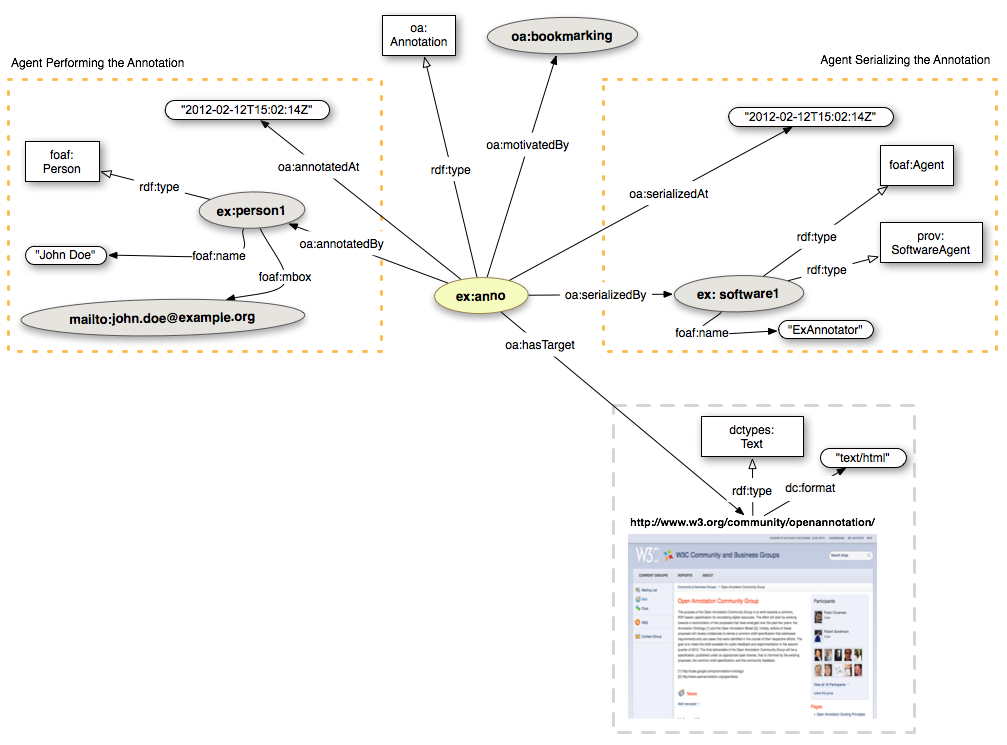
In order to improve human readability, we can add a textual description as a Body.
In this particular example, we are going to embed the textual Body (see specs: Embedded Textual Bodies) through the Content in RDF specification introduces a resource with the class cnt:ContentAsText to represent the content, and a property cnt:chars to hold the content string itself.
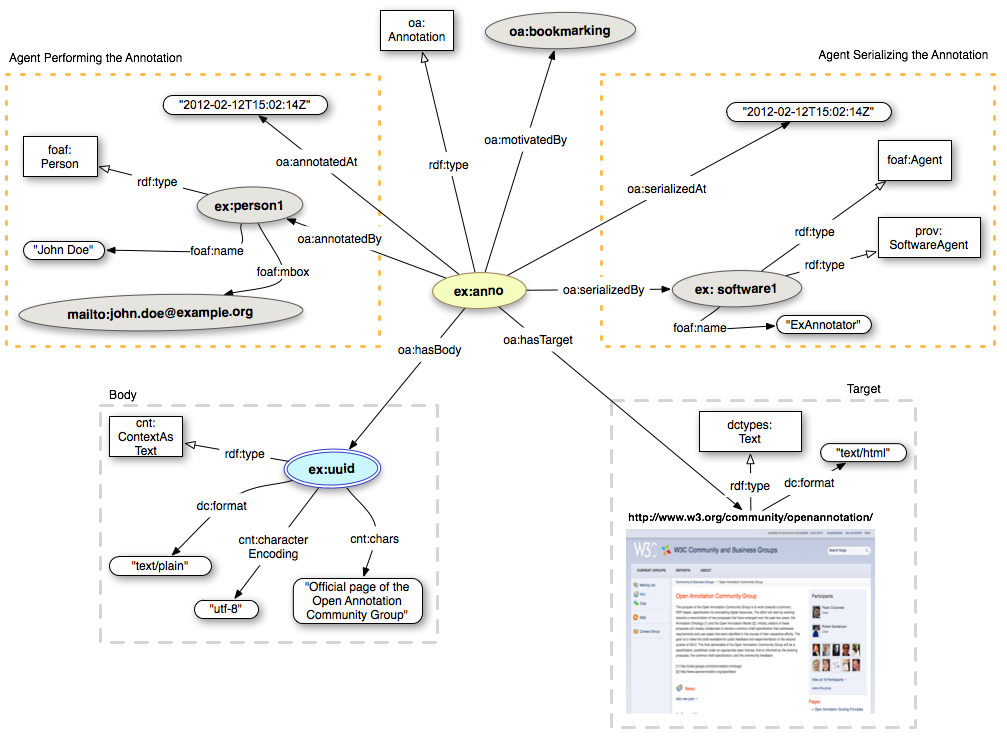
The above example in Turtle RDF format:
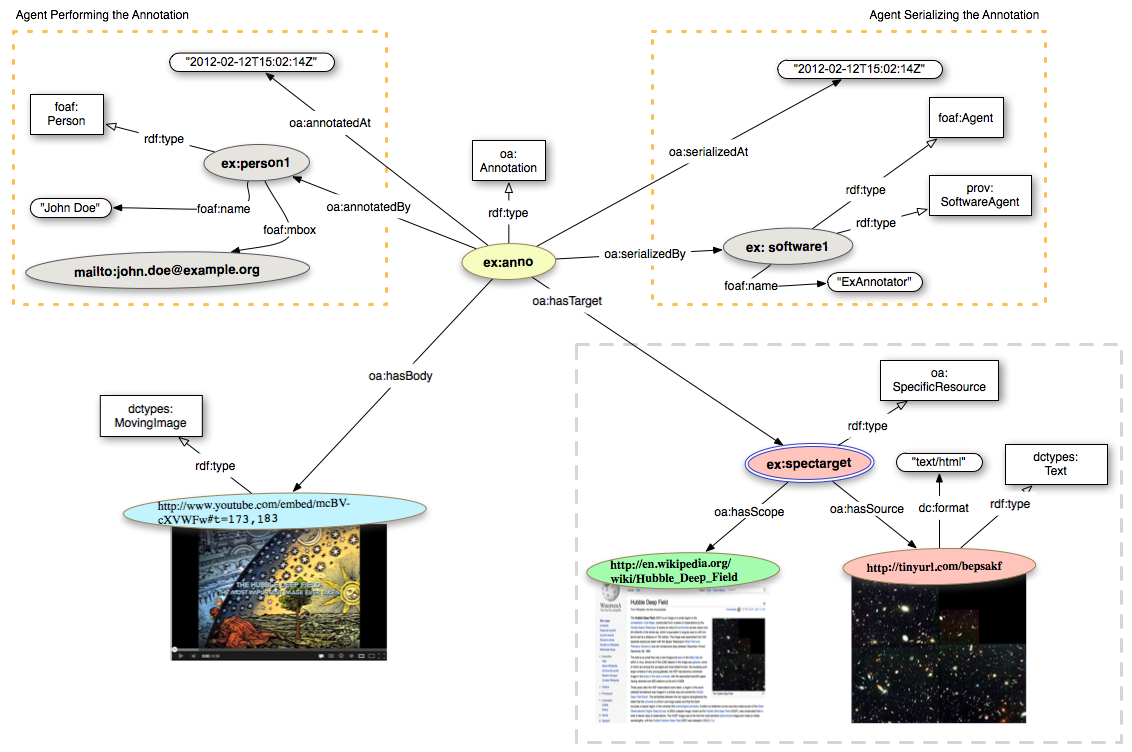
ex:anno a oa:Annotation ; oa:hasTarget <http://www.w3.org/community/openannotation/> ; oa:hasBody ex:uuid ; oa:motivatedBy oa:bookmarking ; oa:annotatedBy ex:person1 ; oa:annotatedAt "2012-02-12T15:02:14Z" ; oa:serializedBy ex:software1 ; oa:serializedAt "2012-02-12T15:02:14Z" . <http://www.w3.org/community/openannotation/> a dctypes:Text dc:format "text/html" . ex:uuid a cnt:ContentAsText ; cnt:chars "Official Page of the Open Annotation Community Group" ; dc:format "text/plain" ; cnt:characterEncoding "utf-8" . ex:person1 a foaf:Person ; foaf:mbox <mailto:john.doe@example.org> ; foaf:name "John Doe" . ex:software1 a foaf:Agent, prov:SoftwareAgent ; foaf:name "ExAnnotator" .
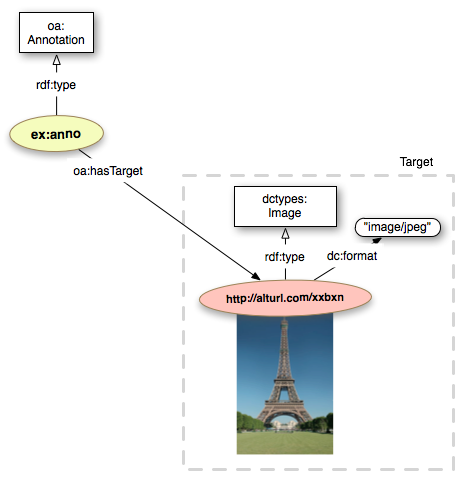
We are now going to create multiple tags for the Wikipedia image of the Eiffel Tower here identified by the URI http://alturl.com/wxidq.we start by creating an instance of the oa:Annotation class; then we link such instance to the image (Target) identified by the URI http://alturl.com/wxidq. Adding the Target content type and the dc:format (dctypes:Image and "image/jpeg"), can be useful for applications consuming the annotation.
We can then provide the oa:Motivation that encodes the reason(s) why the Annotation was created. In this specific case, the Motivation is oa:tagging:
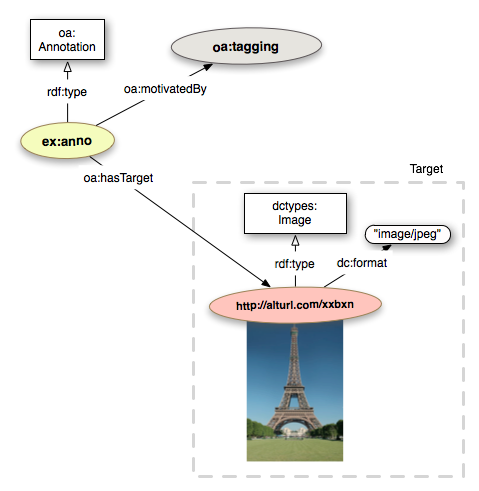
In order to illustrate the different tagging mechanisms supported by the Open Annotation data model we are going to create three different tags:
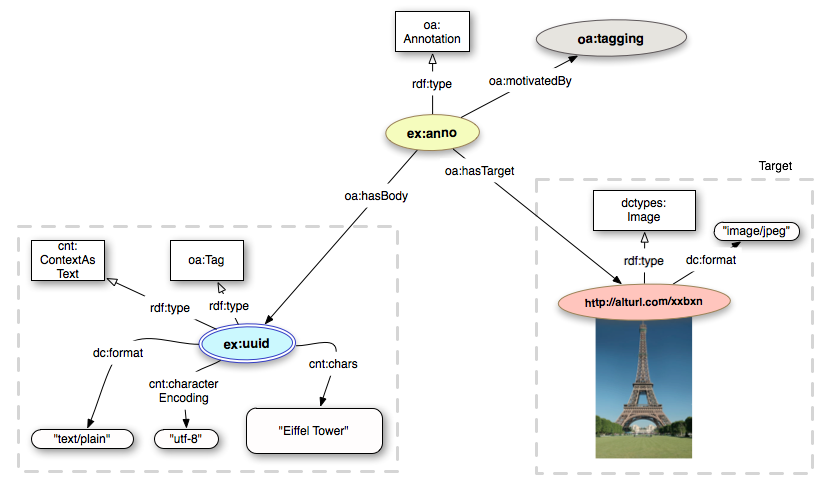
oa:SemanticTag. 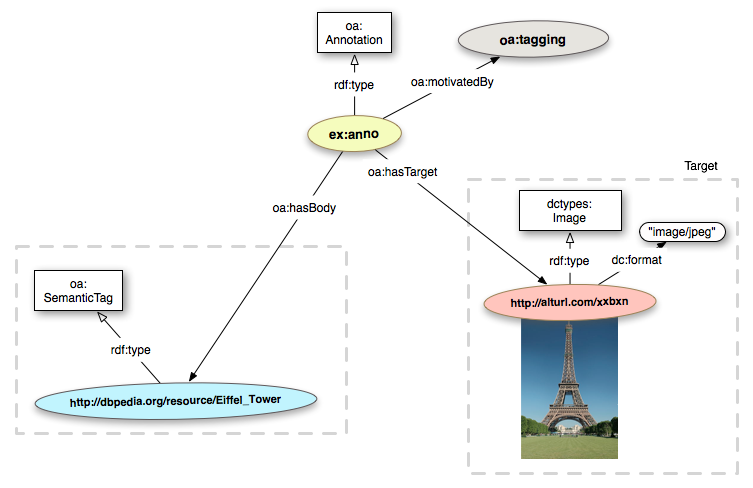
oa:SemanticTag that corresponds to a foaf:page".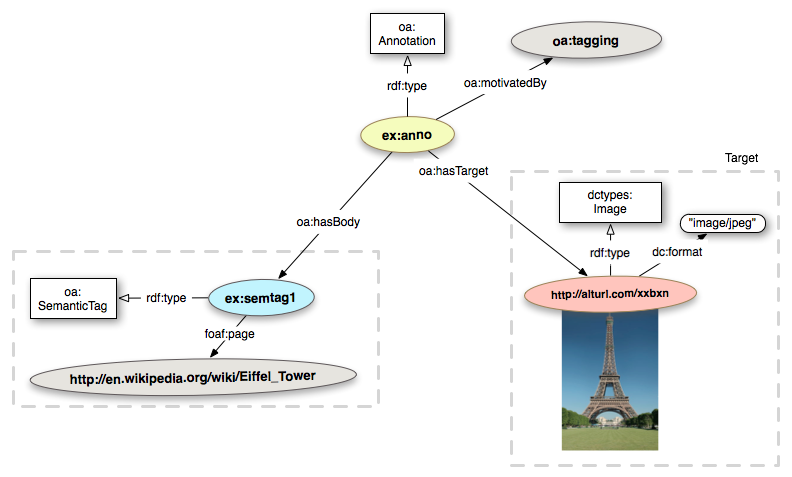
As already mentioned in section 2, the Open Annotation model allows for multiple bodies. Therefore we can now pull together the three different ways of encoding tags in one single annotation. This is just an example, normally you would probably not create three different tags tags for the same entity, unless the goal is to infer mappings.
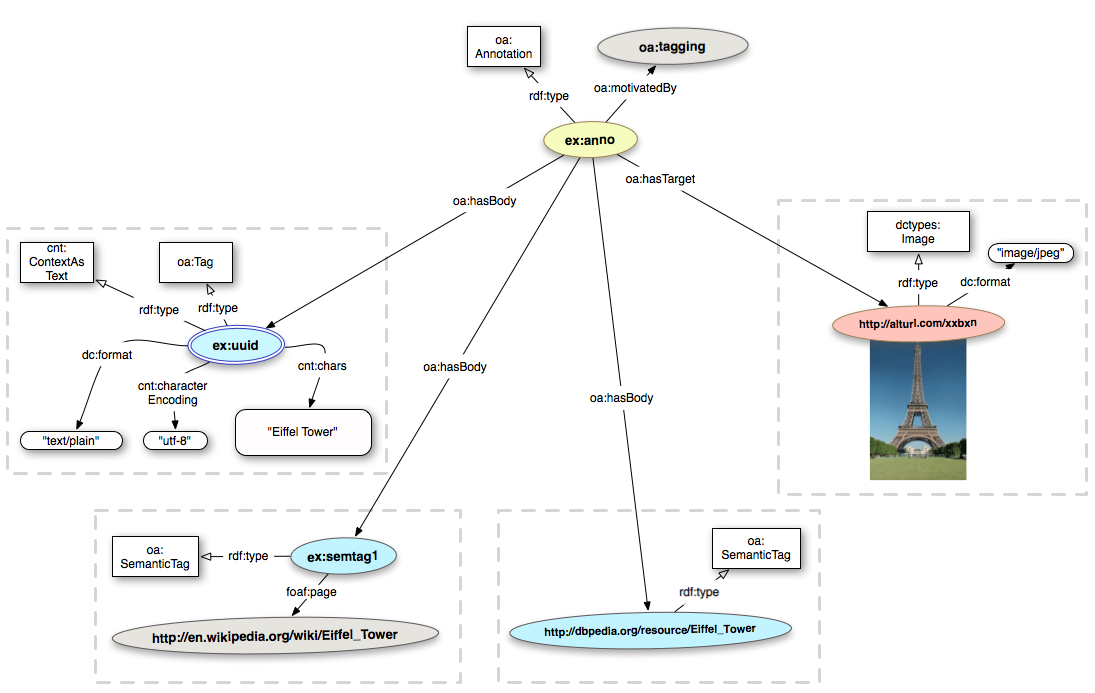
Finally, as in the previous example, we can add provenance
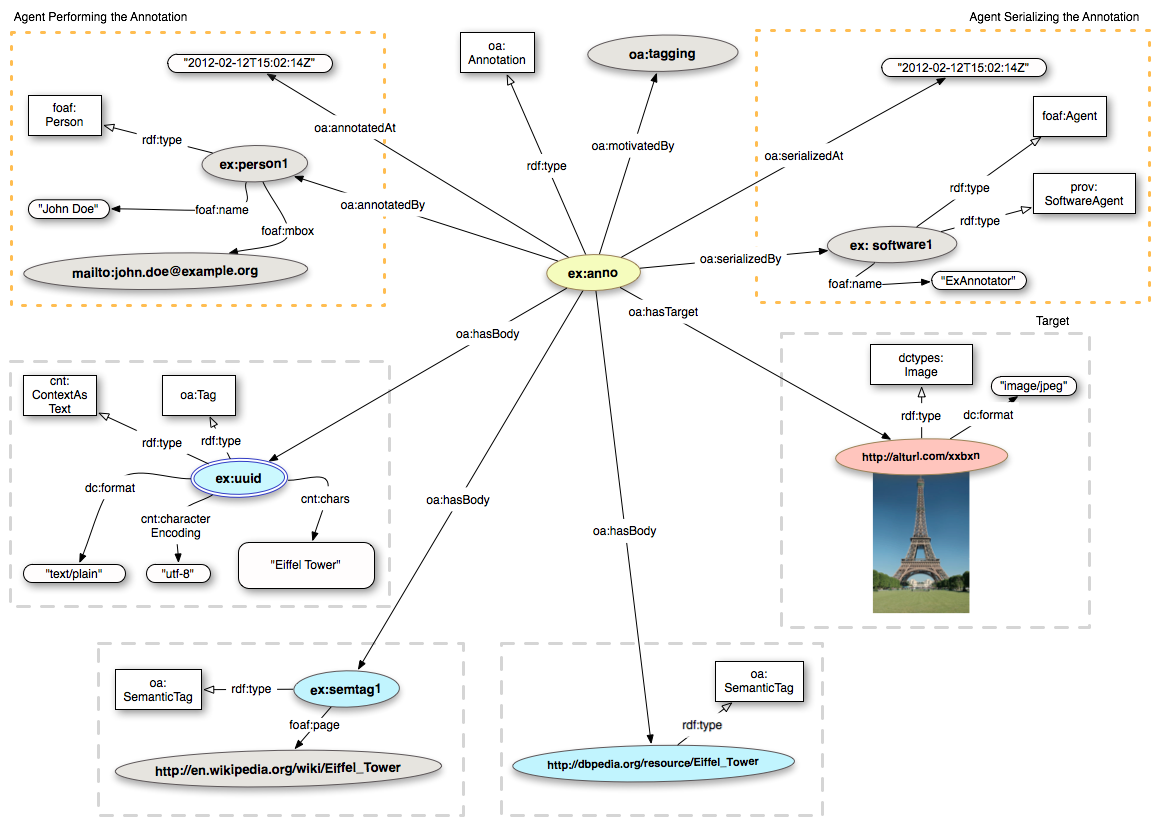
The above example in Turtle RDF format:
ex:anno a oa:Annotation ; oa:hasTarget <http://alturl.com/xxbxn> ; oa:hasBody ex:uuid ; oa:hasBody ex:semtag1 ; oa:hasBody <http://dbpedia.org/resource/Eiffel_Tower>; oa:motivatedBy oa:tagging ; oa:annotatedBy ex:person1 ; oa:annotatedAt "2012-02-12T15:02:14Z" ; oa:serializedBy ex:software1 ; oa:serializedAt "2012-02-12T15:02:14Z" . <http://alturl.com/xxbxn> a dctypes:Image dc:format "image/jpeg" . ex:uuid a cnt:ContentAsText ; cnt:chars "Eiffel Tower" ; dc:format "text/plain" ; cnt:characterEncoding "utf-8" . ex:semtag1 a oa:SemanticTag ; foaf:page <http://en.wikipedia.org/wiki/Eiffel_Tower> . <http://dbpedia.org/resource/Eiffel_Tower> a oa:SemanticTag. ex:person1 a foaf:Person ; foaf:mbox <mailto:john.doe@example.org> ; foaf:name "John Doe" . ex:software1 a foaf:Agent, prov:SoftwareAgent ; foaf:name "ExAnnotator" .
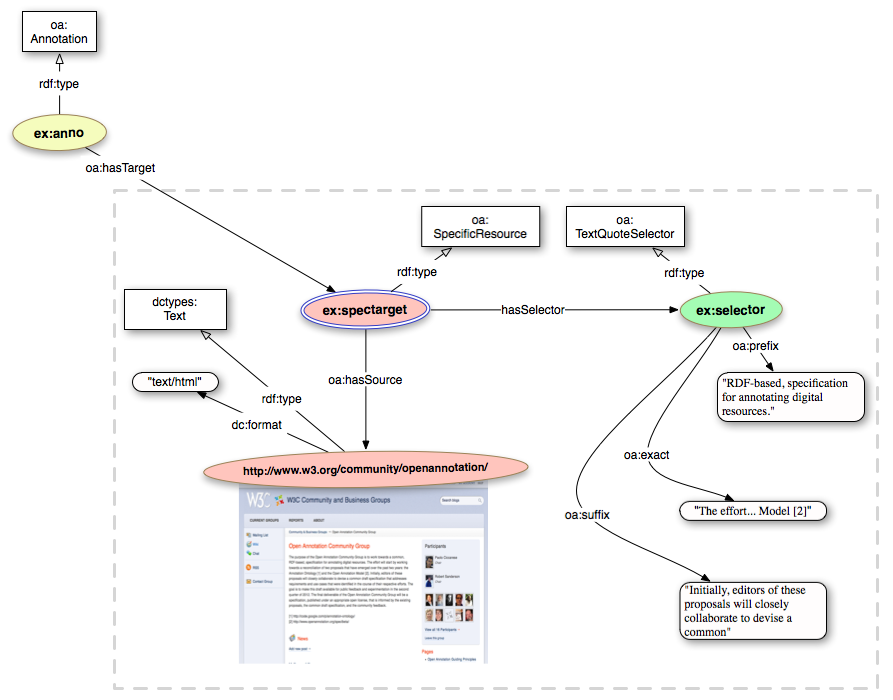
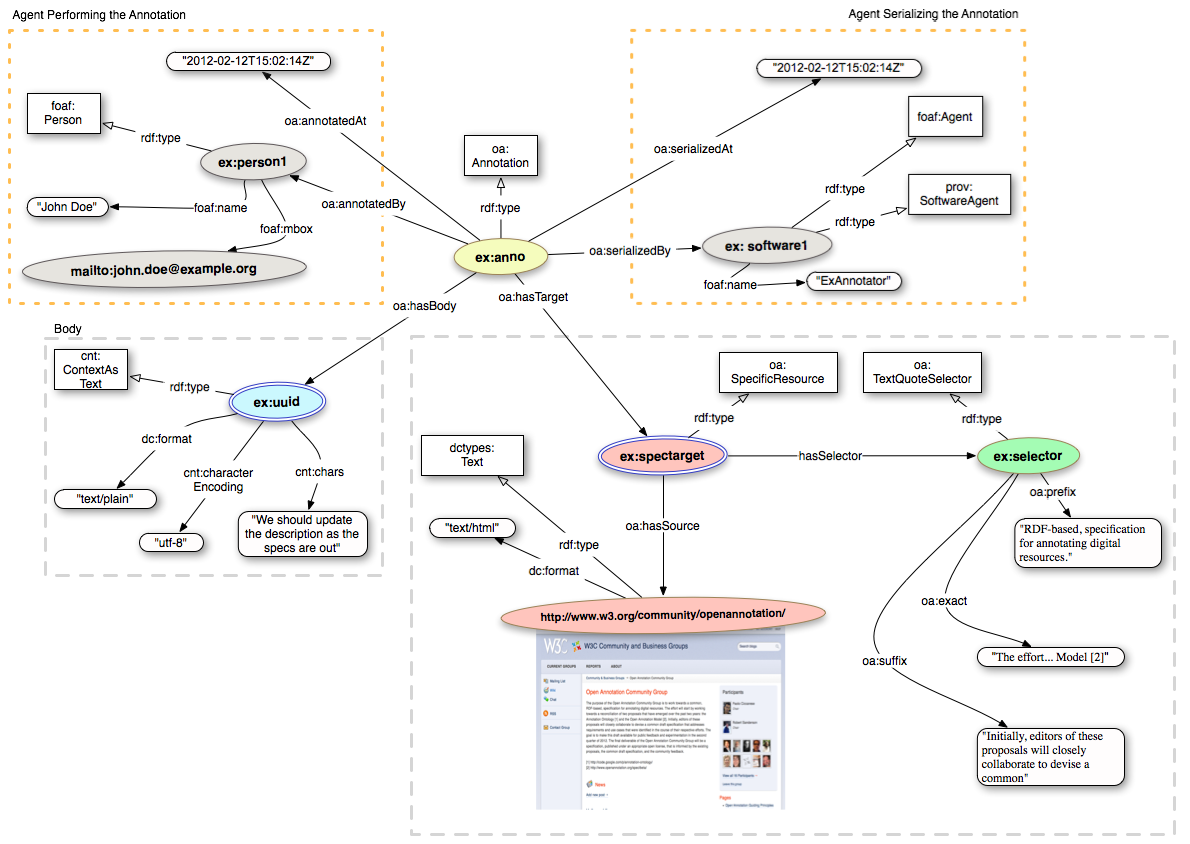
In this example we will select a text fragment in the description displayed in the homepage of the Open Annotation Community Grooup and we will comment on it. (see Figure 17)

We can start by creating the instance of the oa:SpecifResource that is going to link to the original entire resource (Open Annotation Community Group homepage) through the relationship oa:hasSource.
As I am interested in creating an annotation that could potentially display on both the HTML and the PDF version of the same document, I will opt for a Text Quote Selector (see 3.2.2.2 Text Quote Selector). The idea of such selector is simple: we identify the match by defining the text preceeding the match (oa:prefix), the match itself (oa:exact) and the text following the match (oa:suffix).
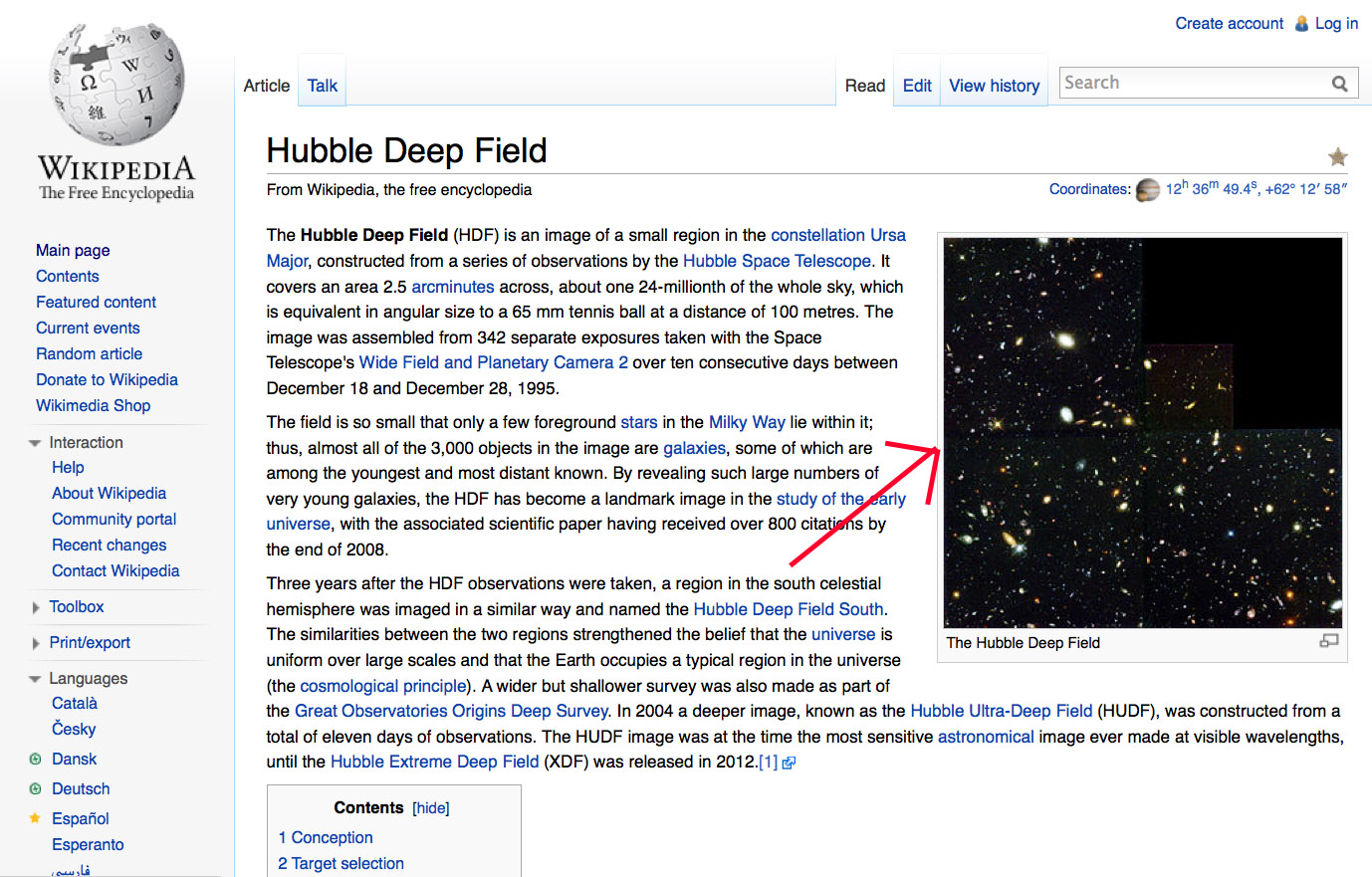
The Wikipedia page about the 'Hubble Deep Field' contains an image (see figure 21).
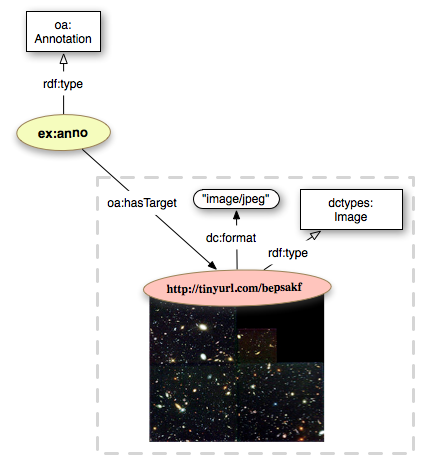
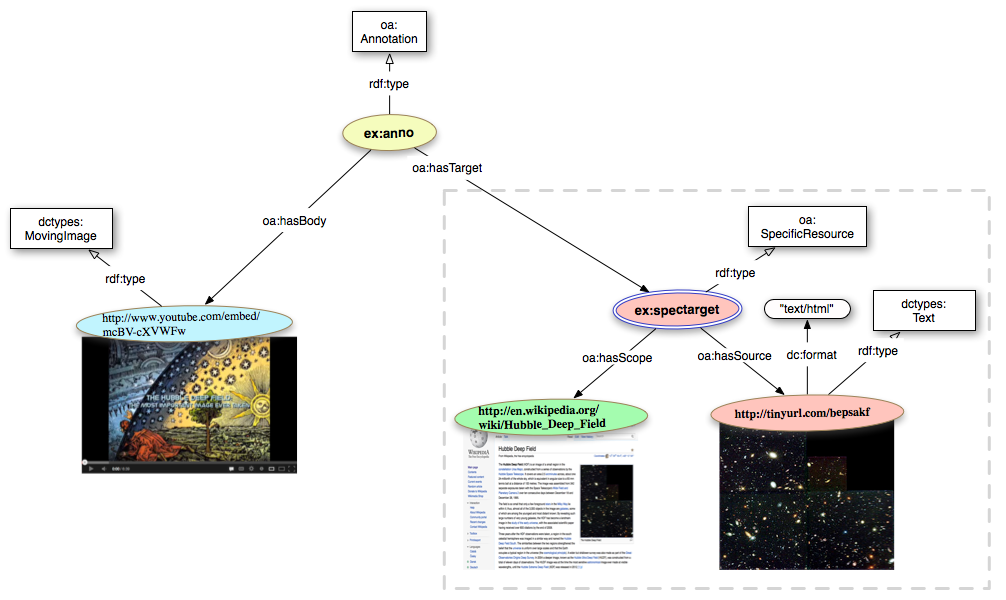
A user creates a video on YouTube that discusses the Hubble Deep Field Image. The video is therefore the Body of the Annotation, and the image is the Target, as the video is about the image. We start by defining the target of our annotation:
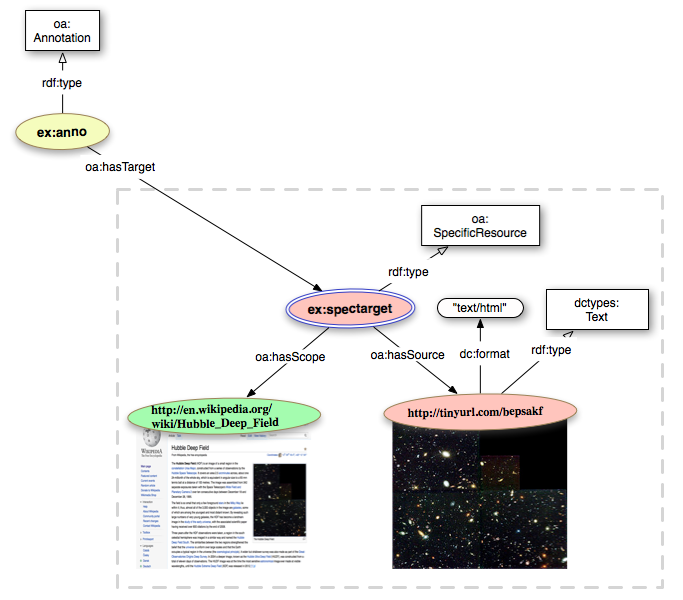
The Open Annotation model gives the option of recording the webpage that the user was looking at while performing the annotation through the use of a SpecificTarget and the relationship hasScope.
We will now define the body of the annotation as the YouTube video.
No normative references.